Com 50 bilhões de parâmetros da Bloomberg, o BloombergGPT supera modelos abertos de tamanho semelhante em tarefas financeiras de NLP por margens significativas – sem comprometer o desempenho em benchmarks gerais de LLM
A Bloomberg divulgou hoje um trabalho de pesquisa detalhando o desenvolvimento do BloombergGPT ™, um novo modelo de inteligência artificial generativa (IA) em larga escala. Esse modelo de linguagem grande (LLM, em inglês) foi especificamente treinado em uma ampla gama de dados financeiros para oferecer suporte a um conjunto diversificado de tarefas de processamento de linguagem natural (PLN) no setor financeiro.
Avanços recentes em Inteligência Artificial (IA) baseados em LLMs já demonstraram novas aplicações interessantes para muitos domínios. No entanto, a complexidade e a terminologia exclusiva do domínio financeiro justificam um modelo específico de domínio. BloombergGPT representa o primeiro passo no desenvolvimento e aplicação desta nova tecnologia para o setor financeiro. Esse modelo ajudará a Bloomberg a melhorar as tarefas de NLP financeiras existentes, como análise de sentimento, reconhecimento de entidade nomeada, classificação de notícias e resposta a perguntas, entre outras. Além disso, o BloombergGPT abrirá novas oportunidades para organizar as vastas quantidades de dados disponíveis no Bloomberg Terminal para melhor ajudar os clientes da empresa, trazendo todo o potencial da IA para o domínio financeiro.
Por mais de uma década, a Bloomberg tem sido pioneira na aplicação de IA, Aprendizado de Máquina e PNL em finanças. Hoje, a Bloomberg oferece suporte a um conjunto muito grande e diversificado de tarefas de PNL que se beneficiarão de um novo modelo de linguagem voltado para finanças. Os pesquisadores da Bloomberg foram pioneiros em uma abordagem mista que combina dados financeiros com conjuntos de dados de uso geral para treinar um modelo que alcança os melhores resultados da categoria em benchmarks financeiros, ao mesmo tempo em que mantém o desempenho competitivo em benchmarks de LLM de uso geral.
Para atingir esse marco, o grupo de pesquisa e produto de ML da Bloomberg colaborou com a equipe de engenharia de IA da empresa para construir um dos maiores conjuntos de dados específicos de domínio até agora, com base nos recursos existentes de criação, coleta e curadoria de dados da empresa. Como uma empresa de dados financeiros, os analistas de dados da Bloomberg coletaram e mantiveram documentos em linguagem financeira ao longo de quarenta anos. A equipe extraiu desse extenso arquivo de dados financeiros para criar um conjunto de dados abrangente de 363 bilhões de tokens, composto por documentos financeiros em inglês.
Esses dados foram aumentados com um conjunto de dados públicos de 345 bilhões de tokens para criar um grande corpus de treinamento com mais de 700 bilhões de tokens. Usando uma parte desse corpus de treinamento, a equipe treinou um modelo de linguagem causal de decodificador de 50 bilhões de parâmetros. O modelo resultante foi validado em benchmarks de NLP específicos para finanças existentes, um conjunto de benchmarks internos da Bloomberg e amplas categorias de tarefas de NLP de propósito geral de benchmarks populares (por exemplo, BIG-bench Hard, Knowledge Assessments, Reading Comprehension e Linguistic Tasks). Notavelmente, o modelo BloombergGPT supera os modelos abertos existentes de tamanho semelhante em tarefas financeiras por grandes margens, enquanto ainda apresenta um desempenho igual ou melhor em benchmarks gerais de NLP.
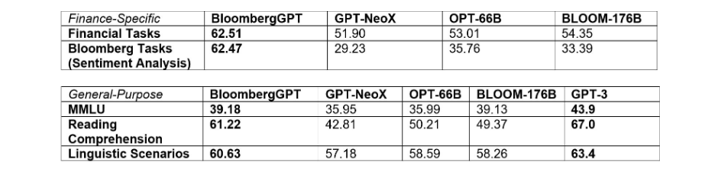 Tabela 1. Como o BloombergGPT funciona em duas grandes categorias de tarefas de PNL: específicas de finanças e de uso geral.
Tabela 1. Como o BloombergGPT funciona em duas grandes categorias de tarefas de PNL: específicas de finanças e de uso geral.
“Por todas as razões pelas quais os LLMs generativos são atraentes – aprendizado em poucas fotos, geração de texto, sistemas de conversação etc. – vemos um enorme valor em ter desenvolvido o primeiro LLM focado no domínio financeiro”, disse Shawn Edwards, diretor de tecnologia da Bloomberg. “O BloombergGPT nos permitirá lidar com muitos novos tipos de aplicativos, ao mesmo tempo em que oferece desempenho muito mais alto pronto para uso do que modelos personalizados para cada aplicativo, em um tempo de lançamento no mercado mais rápido.”
“A qualidade dos modelos de aprendizado de máquina e PNL se resume aos dados que você coloca neles”, explicou Gideon Mann, chefe da equipe de pesquisa e produto de ML da Bloomberg. “Graças à coleção de documentos financeiros que a Bloomberg organizou ao longo de quatro décadas, fomos capazes de criar cuidadosamente um conjunto de dados específico de domínio grande e limpo para treinar um LLM mais adequado para casos de uso financeiro. Estamos entusiasmados em usar o BloombergGPT para melhorar os fluxos de trabalho de NLP existentes, ao mesmo tempo em que imaginamos novas maneiras de colocar esse modelo em prática para encantar nossos clientes”.
Para mais detalhes sobre o desenvolvimento do BloombergGPT, leia o artigo sobre arXiv: https://arxiv.org/abs/2303.17564
##